Conv1D
weightをすべて1。biasをすべて0にした場合、
kernel_size分の要素を足して、filters分の次元数にコピーして出力される。
Conv1D(filters=5, kernel_size=3, padding="same", activation='relu', input_shape=(4,1))
# input data
[
[
[1]
[2]
[3]
[4]
]
]
# output data
[
[
[3. 3. 3. 3. 3.]
[6. 6. 6. 6. 6.]
[9. 9. 9. 9. 9.]
[7. 7. 7. 7. 7.]
]
]
axis2の要素数が増えた場合もすべての要素が足される。
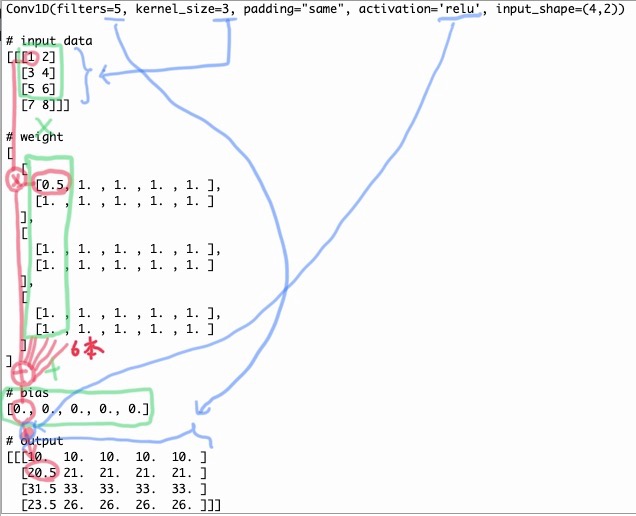
Conv1D(filters=5, kernel_size=3, padding="same", activation='relu', input_shape=(4,2))
# input data
[[[1 2]
[3 4]
[5 6]
[7 8]]]
# output data
[
[
[10. 10. 10. 10. 10.]
[21. 21. 21. 21. 21.]
[33. 33. 33. 33. 33.]
[26. 26. 26. 26. 26.]
]
]
padding=”valid”にすると入力データがない範囲は出力されない。(axis 1の次元数が減る)
Conv1D(filters=5, kernel_size=3, padding="valid", activation='relu', input_shape=(4,1))
# input data
[
[
[1]
[2]
[3]
[4]
]
]
# output
[
[
[6. 6. 6. 6. 6.]
[9. 9. 9. 9. 9.]
]
]
weightとbiasを含めた計算の流れ。

MaxPooling1D
pool_sizeごとに要素のまとまりをつくり、その中の最大値を出力にする。
MaxPooling1D(pool_size=2, padding='same', input_shape=(4,1)))
# input data
[
[
[1],
[2],
[3],
[4],
]
]
# output data
[
[
[2],
[4],
]
]
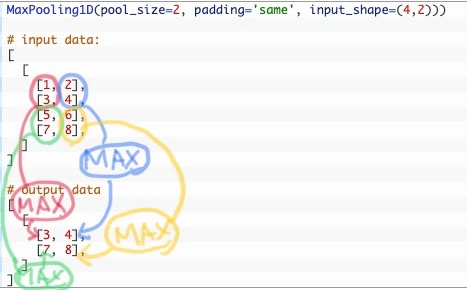
以下のように、axis 2(0ベース)の次元数(要素の数)が多い場合は、同一次元同士を比較して最大値を求める。
つまりaxis 2 の次元数は減らない。axis 1 の次元数は1/pool_sizeになる。
MaxPooling1D(pool_size=2, padding='same', input_shape=(4,2)))
# input data:
[
[
[1, 2],
[3, 4],
[5, 6],
[7, 8],
]
]
# output data
[
[
[3, 4],
[7, 8],
]
]